The Birth of a New Commodity Class and a Spot Market for Inference

The gap between the #1 and #10 AI model shrank from 11.9% to 5.4% in a single year.
Between #1 and #2? From 4.9% down to 0.7%.
This data is reported by Stanford's AI Index, tracking Chatbot Arena scores. The most comprehensive public model leaderboard we have.
For a few years now, choosing a model has felt like a product decision. Pick the "best," wire it into everything, and move on.

That approach made sense when there were clear winners. It is harder to justify when the gap between first and tenth place is five points, and first and second is just a rounding error.
Open-weight models have gotten so good that "closed vs open" is not a binary choice for most production work anymore. Yes, there are real edges at the frontier. But most workloads are not frontier workloads. They are high-volume, latency-sensitive, and cost-constrained.
Claude and Codex still have their own personalities and ways of handling tools. But the real-world gap in production gets a lot smaller once you factor in how models are actually used: prompting strategies, tool calling, retrieval, testing, fallbacks, safety checks. The question that matters in production is not "which model is smartest?" It’s "is this output good enough for our users?"
For a growing number of workloads, the answer is a resounding "yes" across a whole cluster of models.
When quality converges like this, competition moves to price, reliability, and speed of delivery, aka commoditization. And when things commoditize, markets form around them.
Inference is a physical commodity with physical delivery (just like electricity)
This nuance gets glossed over, but it matters for everything that follows.
Inference is not a digital file you can download and store. It runs on real machines, constrained by real physics: chips, power, networking, scheduling. Like electricity, it has to be consumed in real time. There’s no point to stockpile it for later.
You can trade units of inference as a standardized, interchangeable claim on an order book, then you receive delivery as actual routed API traffic. This is similar to how electricity is traded and transmitted. Inference a true spot commodity.
And in fact, people are already doing something like this. Just without any of the market structure.
A market for inference already exists, but there is no true price discovery and everyone suffers from vendor lock-in
How do we know this? There is an early smell test for something that wants to become a market: seeing fragmented price sheets for basically the same product.
Look at some of the providers listing Kimi K2.5 right now:
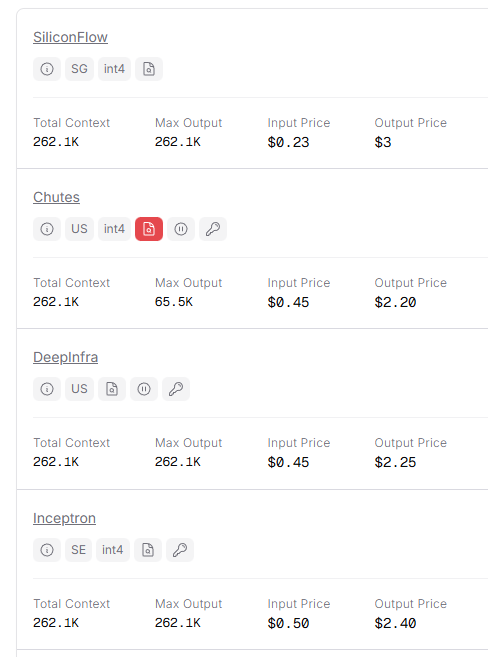
Same model. Different providers. Different prices. No central venue. No order book. Everyone locked into their own bilateral deals.
The same starting conditions were present for every commodity market that has ever emerged.
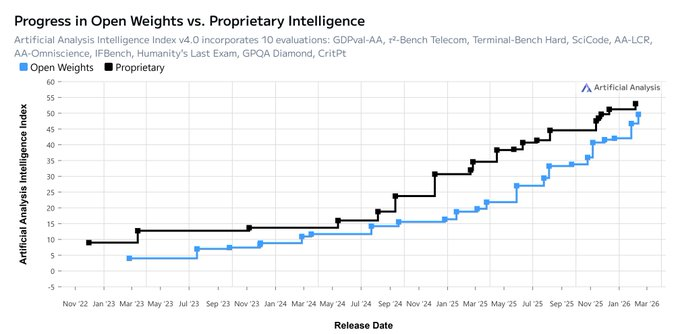
Standardization is what converts fragmented pricing into a real order book. Markets form around things that are substitutable and fungible. Models do not need to be identical. They just need to be interchangeable within a specification.
The obvious next step is to list individual models on an order book but that wont work
If you build an order book around specific LLMs, or worse, specific snapshots, you create instruments that expire faster than they can accumulate liquidity. Every major model release forces a relist. Liquidity splinters across ghost books nobody trades.
You're also seeing this happen across all major model labs. All model endpoints have explicit retirement schedules. OpenAI's deprecations page is a running list of models being tagged legacy, migrated, or removed.
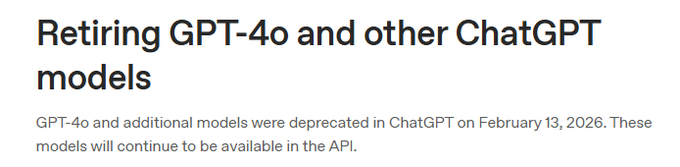
You cannot build a liquid market on top of instruments with a built-in shelf life of a few months.
This is not a new problem though. Every physical commodity went through the same phase before its market matured.
Commodity exchanges solved this problem a long time ago by refusing to list "brands." They list deliverable specifications with standards and grades.
Check out the corn specs on the CME. The contract is not "corn grown with Tractor Brand X." It is a standardized deliverable defined by contract size and grade: 5,000 bushels, No. 2 Yellow as par, other grades deliverable at premiums or discounts.
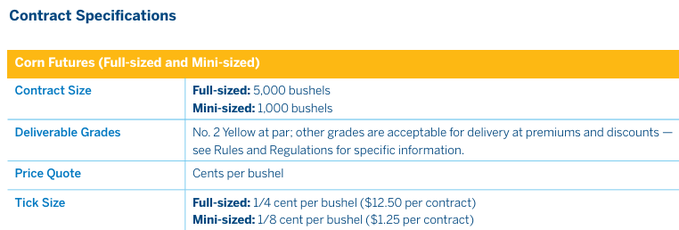
The exchange cares about what shows up at delivery. Not which plow, seed brand, or tractor got it there.
Users don't care about the brand of the model or what hardware computed the output. Same principle applies for Inference.
AI app devs must ponder more on defining what the output must do, rather than analyzing and choosing which model should produce it.
From prescriptive to descriptive: Task-based markets and commodity-style specifications for intelligence
Abstract away the model and the chip. Yes, both.
If you list "GPU-hours," you inherit hardware heterogeneity and constant platform drift. If you list "Model X," you inherit deprecation cycles and version churn. Both paths embed obsolescence into the instrument.
Both layers will keep changing. That's a feature, not a problem, unless you have baked them into your contract design.
The stable unit is the work output. The task.
Define the deliverable by what the output must achieve: intelligence floor, latency, throughput minimum.
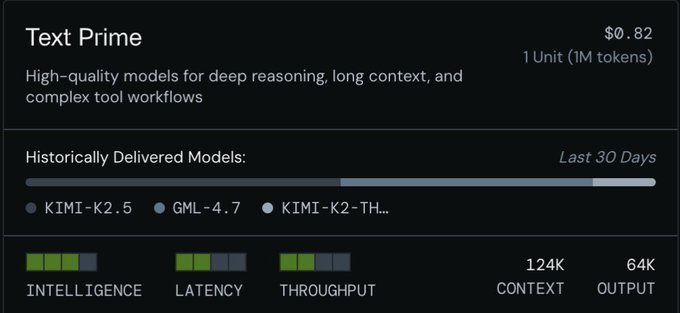

Let suppliers figure out how to deliver and compete on edge, not branding.
Once the contract has its specifications, suppliers compete on real edges: better hardware efficiency, smarter batching and scheduling, better model post-training and distillation, more resilient routing and failure handling. As long as they clear the thresholds, they can serve into the market.
This is how commodity markets have always preserved innovation without rewriting the contract every time the underlying technology changes. The exchange sets grades and enforcement. Suppliers innovate inside the box. Price clears the competition.
Models and hardware become what they should be: implementation details.
The agent economy will be a native customer of an inference exchange
Inference is the fuel that powers agents.
Agents are not going to care about model brand names. They care about steady service and deliverables they can count on. If another supplier steps up and meets the spec, they will switch without a second thought.
Agents need contracts matched to the job: chat, coding, trading, customer support etc. An agent grabs a contract like Text_Prime/USD, the supplier delivers on the terms, and the contract itself keeps everyone honest.
If agents are going to be self-sustaining, they need to watch their budgets and make sure they do not go down. A real market lets them lock in supply, compare prices across suppliers, hedge costs, and jump on price gaps. Agents will buy spot inference, manage their own procurement, and do it autonomously.
The agent earns, buys its own fuel, gets the job done, and does it all over again.
Machine GDP, the Intelligence Index, Efficiency Spreads and beyond
Metering inference as a standard, deliverable unit makes something new possible: calculating Machine GDP. Real unit economics for how much standardized machine work is produced, at what cost, at what clearing price, and how much economic surplus the machine economy generates alongside human GDP.
You can also figure out exactly what it costs to deliver a unit of intelligence: GPU, power, labor, overhead etc. Compare that against what buyers actually pay. The gap between production cost and clearing price is an efficiency spread. When demand spikes or supply runs short, the spread widens. When supply is plentiful or the tech improves, it narrows. Same mechanics as a spark spread in energy markets.
Once you have spot price discovery, the rest of the financial stack tends to follow: forwards for planning, capacity products for availability, and eventually derivatives for hedging and speculation.
Every commodity that hit this level of economic importance went through the same sequence.
Inference is next.
Join our beta testing and Enter The Grid